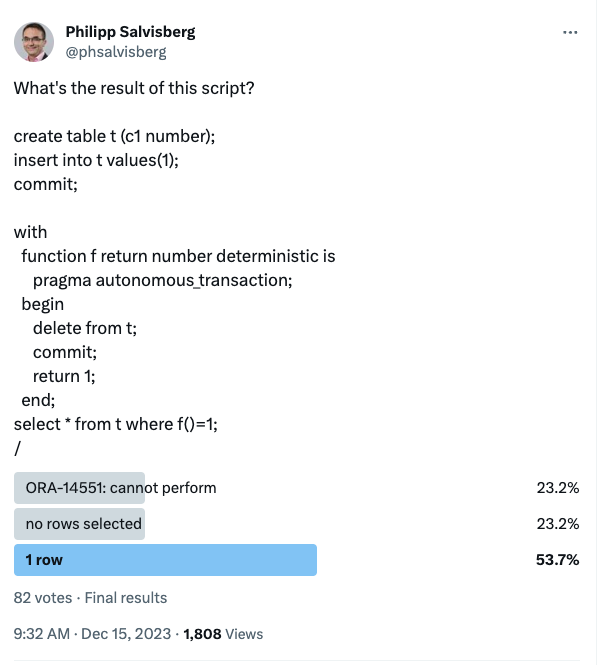
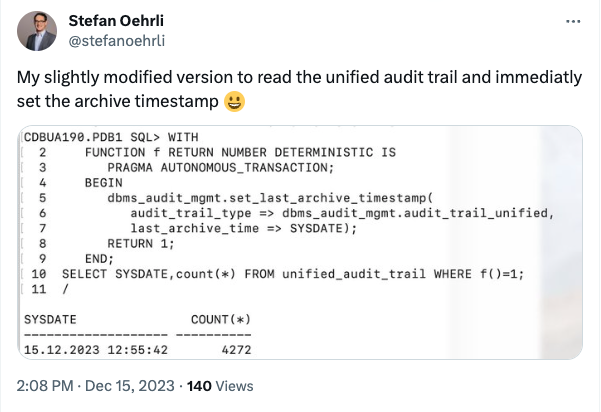
Introduction
In the last episode we extended the IslandSQL grammar to cover all DML statements as single lexer token. Now it’s time to handle the complete grammar for one DML statement. The simplest one is lock table. A good reason to start with it and lay the foundation for the other DML commands.
The full source code is available on GitHub and the binaries on Maven Central.
Grammars in SQL Scripts
When using SQL scripts, we work with several grammars. There is always more than one grammar involved. It depends on your use case how much more.
The candidates when working with an Oracle Database 21c are:
- SQL*Plus
- SQLcl
- PGQL
- SQL
- PL/SQL
- Java
- more hidden in strings and LOBs such as XML, XSLT, JSON, …
The number of grammars is growing. For example, we expect JavaScript stored procedures in Oracle Database 23c.
In the previous episodes, we have primarily dealt with SQL*Plus and SQL as a whole. Before we deal with a specific SQL statement such as lock table, we need to know where a SQL statement starts and where it ends. The start seems obvious, but the end? Is the fragment SQL_END correctly describing the end of a SQL statement?
fragment SQL_END:
EOF
| (';' [ \t]* SINGLE_NL?)
| SLASH_END
;
Where Does a SQL Statement End?
A common misconception is, that a SQL statement ends with a semicolon. This seems to be true when you only look at the syntax per statement in the Oracle Database documentation, but it is not. Here’s an example:
begin
execute immediate '
lock table dept in exclusive mode
';
end;
/The anonymous PL/SQL block executes a dynamic lock table statement on line 3. Please note that the lock table statement starts with whitespace and ends on whitespace. We do not pass a semicolon as part of the execute immediate statement. This anonymous PL/SQL block completes successfully when the connected user can lock emp.
However, when we add a semicolon at the end of the lock table statement we get the following error:
Error starting at line : 1 in command -
begin
execute immediate '
lock table dept in exclusive mode;
';
end;
Error report -
ORA-00933: SQL command not properly ended
ORA-06512: at line 2
00933. 00000 - "SQL command not properly ended"
*Cause:
*Action:It’s not allowed to terminate a SQL statement with a semicolon in dynamic SQL and therefore also when executing SQL via JDBC or ODBC.
But what is the semicolon for? Well, it terminates a SQL statement within a SQL*Plus or SQLcl script. In SQL*Plus you can change the behaviour using the set sqlterminator command.
The following script works in SQL*Plus (but not in SQLcl, it’s a documented limitation):
set sqlterminator $ lock table dept in exclusive mode$
The semicolon is the default terminator of SQL statement in SQL scripts. The semicolon is part of the SQL*Plus grammar but not part of the SQL grammar. However, it is more. It is also the only supported statement terminator in PL/SQL as the following SQL*Plus script shows.
set sqlterminator $ begin lock table dept in exclusive mode; end; /
The semicolon on line 4 terminates the anonymous PL/SQL block. It’s part of the PL/SQL grammar. The final slash is not part of the anonymous PL/SQL block. It is an alternative to the SQL*Plus run command. It sends the buffer (the anonymous PL/SQL block) to the database server.
By the way, the Oracle Database documentation explains why it uses the semicolon in its grammar. Here is the corresponding quote:
Note: SQL statements are terminated differently in different programming environments. This documentation set uses the default SQL*Plus character, the semicolon (;).
— Lexical Conventions, SQL Language Reference. Oracle Datase 21c
Yes, the semicolon is part of the SQL*Plus grammar. There is no common sequence of characters for identifying the end of an SQL statement.
What Are We Going to Do Now?
I initially wanted to use ANTLR modes to handle the complete grammar of chosen statements. However, ANTLR modes require that you can identify the start and the end of a mode. For the lock mode statement, the start is the lock keyword and the end is the SQL_END fragment as we used before. We could also use just the semicolon to determine the end. While this works for the lock table statement, it will cause some problems when trying to integrate the PL/SQL grammar.
How do we find out whether a semicolon belongs to a PL/SQL statement or to an SQL statement? Is this possible in the lexer? Well, I think it’s possible by doing some sematic predicate acrobatics, but I don’t think it’s sensible.
Another approach is to use two lexers. The first one, extracting the relevant statement in scope of the IslandSQL grammar. And the second lexer, processing only the extracted statements. The parser uses the token stream from the second lexer. Perfect. However, we want to keep the original positions (line/column) of the tokens in scope. They are important for navigating to the right place in the code. How do we do that?
Keep Hidden Tokens as Whitespace
The idea is to replace all non-whitespace characters in hidden tokens with a space. This way the number of lines and the position in the line of all relevant tokens stay the same. The total number of characters are also the same (the number of bytes might change when multibyte characters are replaced).
Here’s an example.
/* =========================================== * ignore multiline comment * =========================================== */ select * from dual; rem ignore remark: select * from dual; -- ignore single line comment lock table dept in exclusive mode;
After the transformation the script should look like this.
.............................................. ........................... ................................................. select * from dual; ...................................... ............................. lock table dept in exclusive mode;
Please note that a dot(.) represents a replaced character. Read a dot as a space.
We can use this converted script as input for the second lexer.
The implementation is relatively easy. I renamed the original lexer to IslandSqlScopeLexer und used this code for the transformation:
static public String getScopeText(CommonTokenStream tokenStream) {
TokenStreamRewriter rewriter = new TokenStreamRewriter(tokenStream);
tokenStream.fill();
tokenStream.getTokens().stream()
.filter(token -> token.getChannel() == Token.HIDDEN_CHANNEL
&& token.getType() != IslandSqlScopeLexer.WS)
.forEach(token -> {
StringBuilder sb = new StringBuilder();
token.getText().codePoints().mapToObj(c -> (char) c)
.forEach(c -> sb.append(c == '\t' || c == '\r' || c == '\n' ? c : ' '));
rewriter.replace(token, sb.toString());
}
);
return rewriter.getText();
}The method gets a token stream as input and returns the transformed text (SQL script).
The ANTLR runtime comes with a TokenStreamRewriter that helps adding, deleting or changing tokens. We are only changing hidden tokens that are not of type whitespace. Tabs, carriage returns and line feeds are kept. Other characters are replaced by a space.
The New Lexer
After the preprocessing of the original input we can concentrate on the islands. The sea is representated as whitespace. This simplifies the logic of the lexer.
lexer grammar IslandSqlLexer;
options {
superClass=IslandSqlLexerBase;
caseInsensitive = true;
}
/*----------------------------------------------------------------------------*/
// Fragments to name expressions and reduce code duplication
/*----------------------------------------------------------------------------*/
fragment SINGLE_NL: '\r'? '\n';
fragment COMMENT_OR_WS: ML_COMMENT|SL_COMMENT|WS;
fragment SQL_TEXT: (ML_COMMENT|SL_COMMENT|STRING|.);
fragment SLASH_END: SINGLE_NL WS* '/' [ \t]* (EOF|SINGLE_NL);
fragment PLSQL_DECLARATION_END: ';'? [ \t]* (EOF|SLASH_END);
fragment SQL_END:
EOF
| (';' [ \t]* SINGLE_NL?)
| SLASH_END
;
/*----------------------------------------------------------------------------*/
// Hidden tokens
/*----------------------------------------------------------------------------*/
WS: [ \t\r\n]+ -> channel(HIDDEN);
ML_COMMENT: '/*' .*? '*/' -> channel(HIDDEN);
SL_COMMENT: '--' .*? (EOF|SINGLE_NL) -> channel(HIDDEN);
CONDITIONAL_COMPILATION_DIRECTIVE: '$if' .*? '$end' -> channel(HIDDEN);
/*----------------------------------------------------------------------------*/
// Keywords
/*----------------------------------------------------------------------------*/
K_EXCLUSIVE: 'exclusive';
K_FOR: 'for';
K_IN: 'in';
K_LOCK: 'lock';
K_MODE: 'mode';
K_NOWAIT: 'nowait';
K_PARTITION: 'partition';
K_ROW: 'row';
K_SHARE: 'share';
K_SUBPARTITION: 'subpartition';
K_TABLE: 'table';
K_UPDATE: 'update';
K_WAIT: 'wait';
/*----------------------------------------------------------------------------*/
// Special characters
/*----------------------------------------------------------------------------*/
AT_SIGN: '@';
CLOSE_PAREN: ')';
COMMA: ',';
DOT: '.';
OPEN_PAREN: '(';
SEMI: ';';
SLASH: '/';
/*----------------------------------------------------------------------------*/
// Data types
/*----------------------------------------------------------------------------*/
STRING:
'n'?
(
(['] .*? ['])+
| ('q' ['] '[' .*? ']' ['])
| ('q' ['] '(' .*? ')' ['])
| ('q' ['] '{' .*? '}' ['])
| ('q' ['] '<' .*? '>' ['])
| ('q' ['] . {saveQuoteDelimiter1()}? .+? . ['] {checkQuoteDelimiter2()}?)
)
;
INT: [0-9]+;
/*----------------------------------------------------------------------------*/
// Identifier
/*----------------------------------------------------------------------------*/
QUOTED_ID: '"' .*? '"' ('"' .*? '"')*;
ID: [\p{Alpha}] [_$#0-9\p{Alpha}]*;
/*----------------------------------------------------------------------------*/
// Islands of interest as single tokens
/*----------------------------------------------------------------------------*/
CALL:
'call' COMMENT_OR_WS+ SQL_TEXT+? SQL_END
;
DELETE:
'delete' COMMENT_OR_WS+ SQL_TEXT+? SQL_END
;
EXPLAIN_PLAN:
'explain' COMMENT_OR_WS+ 'plan' COMMENT_OR_WS+ SQL_TEXT+? SQL_END
;
INSERT:
'insert' COMMENT_OR_WS+ SQL_TEXT+? SQL_END
;
MERGE:
'merge' COMMENT_OR_WS+ SQL_TEXT+? SQL_END
;
UPDATE:
'update' COMMENT_OR_WS+ SQL_TEXT+? 'set' COMMENT_OR_WS+ SQL_TEXT+? SQL_END
;
SELECT:
(
('with' COMMENT_OR_WS+ ('function'|'procedure') SQL_TEXT+? PLSQL_DECLARATION_END)
| ('with' COMMENT_OR_WS+ SQL_TEXT+? SQL_END)
| (('(' COMMENT_OR_WS*)* 'select' COMMENT_OR_WS SQL_TEXT+? SQL_END)
)
;
/*----------------------------------------------------------------------------*/
// Any other token
/*----------------------------------------------------------------------------*/
ANY_OTHER: . -> channel(HIDDEN);
Options
The options are the same as in IslandSqlScopeLexer. We need the superclass IslandSqlLexerBase only in the STRING rule to handle all quote identifiers supported by the Oracle Database.
Fragments
We moved the fragments section to the top. The fragments CONTINUE_LINE, SQLPLUS_TEXT and SQLPLUS_END are not required in this lexer. They are used in IslandSqlLexerBase to identify SQL*Plus commands as hidden tokens.
Since we replaced all SQL*Plus commands with whitespace there is no need to handle SQL*Plus commands in this lexer.
Hidden Tokens
In this section we define the tokens that we do not need in the parser. Therefore we place them on the hidden channel.
Wait, weren’t the hidden tokens replaced by whitespace? Yes, but only those that were not part of other tokens. However, the statements in scope (represented as a single token in IslandSqlScopeLexer) contain whitespace characters and maybe also comments or even conditional compilation directives (e.g. in plsql_declarations of a select statement). At the current stage of the grammar the CONDITIONAL_COMPILATION_DIRECTIVE is de facto unused. We will need it (or some adequate replacement) once we are going to implement the select statement or other statements containing PL/SQL code.
Keywords
It’s a good practice to define a rule for each token. This way we can control the names of the constants generated by ANTLR. We prefix the keywords with a K_ to distinguish them from other rules/tokens. These keywords can also be used as identifiers in various contexts. At the current stage of the grammar this section contains only the keywords used in the lock table statement of the Oracle Database 21c.
Special Characters
The lock table statement uses these special characters.
Data Types
The STRING rule is the same as in IslandSqlScopeLexer. It is a complete definition of a text literal. The INT rule is new. It defines an unsigned integer.
In a future version of the grammar we will need to support all numeric literals. And of course also date literals and interval literals. We will split the implementation between the lexer and the parser. That will be a bit tricky. For now, let’s keep it simple. – An unsigned integer works in most cases.
Identifier
In the lexer we define two types of identifier. Quoted and nonquoted Identifiers. See also Database Object Naming Rules. See also my blog post regarding unnecessary quoted identifers.
Islands of Interest as Single Token
This is the same list of rules as in IslandSqlScopeLexer. The only rule that is missing is LOCK_TABLE since we are tokenizing this SQL statement completely.
Please note that the UPDATE rule includes a set keyword. This is necessary because the keyword update is also part of the lock table statement. Without this change a lock table emp in share update mode nowait; statement would be partly identified als update statement (update mode nowait;).
The final version of the lexer will not contain statements as single tokens.
Any Other Token
As in IslandSqlScopeLexer we put any other character on the hidden channel. This suppresses some errors in the parser. For example, we can insert a euro sign (€) or a pound sign (£) almost anywhere in the code without causing an error.
In future versions of the lexer, we will put the ANY_OTHER token on the DEFAULT_CHANNEL to avoid this kind of error suppression.
Parser Changes
The changes to the previous version of the parser are highlighted.
parser grammar IslandSqlParser;
options {
tokenVocab=IslandSqlLexer;
}
/*----------------------------------------------------------------------------*/
// Start rule
/*----------------------------------------------------------------------------*/
file: dmlStatement* EOF;
/*----------------------------------------------------------------------------*/
// Data Manipulation Language
/*----------------------------------------------------------------------------*/
dmlStatement:
callStatement
| deleteStatement
| explainPlanStatement
| insertStatement
| lockTableStatement
| mergeStatement
| selectStatement
| updateStatement
;
callStatement: CALL;
deleteStatement: DELETE;
explainPlanStatement: EXPLAIN_PLAN;
insertStatement: INSERT;
mergeStatement: MERGE;
updateStatement: UPDATE;
selectStatement: SELECT;
/*----------------------------------------------------------------------------*/
// Lock table
/*----------------------------------------------------------------------------*/
lockTableStatement:
stmt=lockTableStatementUnterminated sqlEnd
;
lockTableStatementUnterminated:
K_LOCK K_TABLE objects+=lockTableObject (COMMA objects+=lockTableObject)*
K_IN lockmode=lockMode K_MODE waitOption=lockTableWaitOption?
;
lockTableObject:
(schema=sqlName DOT)? table=sqlName
(
partitionExtensionClause
| (AT_SIGN dblink=qualifiedName)
)?
;
partitionExtensionClause:
(K_PARTITION OPEN_PAREN name=sqlName CLOSE_PAREN) # partition
| (K_PARTITION K_FOR OPEN_PAREN
(keys+=expression (COMMA keys+=expression)*) CLOSE_PAREN) # partitionKeys
| (K_SUBPARTITION OPEN_PAREN name=sqlName CLOSE_PAREN) # subpartition
| (K_SUBPARTITION K_FOR OPEN_PAREN
(keys+=expression (COMMA keys+=expression)*) CLOSE_PAREN) # subpartitionKeys
;
// TODO: complete according https://github.com/IslandSQL/IslandSQL/issues/11
expression:
STRING # stringLiteral
| INT # integerLiteral
| sqlName # sqlNameExpression
;
lockMode:
(K_ROW K_SHARE) # rowShare
| (K_ROW K_EXCLUSIVE) # rowExclusive
| (K_SHARE K_UPDATE) # shareUpdate
| (K_SHARE) # share
| (K_SHARE K_ROW K_EXCLUSIVE) # shareRowExclusive
| (K_EXCLUSIVE) # exclusive
;
lockTableWaitOption:
K_NOWAIT # nowait
| K_WAIT waitSeconds=INT # wait
;
/*----------------------------------------------------------------------------*/
// Identifiers
/*----------------------------------------------------------------------------*/
keywordAsId:
K_EXCLUSIVE
| K_FOR
| K_IN
| K_LOCK
| K_MODE
| K_NOWAIT
| K_PARTITION
| K_ROW
| K_SHARE
| K_SUBPARTITION
| K_TABLE
| K_UPDATE
| K_WAIT
;
unquotedId:
ID
| keywordAsId
;
sqlName:
unquotedId
| QUOTED_ID
;
qualifiedName:
sqlName (DOT sqlName)*
;
/*----------------------------------------------------------------------------*/
// SQL statement end, slash accepted without preceeding newline
/*----------------------------------------------------------------------------*/
sqlEnd: EOF | SEMI | SLASH;
Data Manipulation Language
The only visible change in this section is the title. However, there is an important change regarding lockTableStatement. It’s not a simple rule referring to a lexer token anymore.
Lock Table
lockTableStatement
On line 40-42 we define the lockTableStatement. It starts with a lockTableStatementUnterminated and ends on sqlEnd. It contains the same number of characters as in the previous parser version. As a result the extension for Visual Studio Code finds the same lock table statements as before.
lockTableStatementUnterminated
On line 44-47 we define the lockTableStatementUnterminated according the Oracle Database SQL Language Reference 21c with the following three fields:
objectsas an array oflockTableObjectswith at least one entrylockModethat refers to an mandatory instance oflockMode-
waitOptionthat refers to an optional instance oflockTableWaitOption
Based on that ANTLR generates a IslandSqlParser class with a nested class LockTableStatementUnterminatedContext.
public class IslandSqlParser extends Parser {
...
public static class LockTableStatementUnterminatedContext extends ParserRuleContext {
public LockTableObjectContext lockTableObject;
public List<LockTableObjectContext> objects = new ArrayList<LockTableObjectContext>();
public LockModeContext lockmode;
public LockTableWaitOptionContext waitOption;
...
}
...
}The parser populates an instance of LockTableStatementUnterminatedContext according the input. Interesting is, that there is a redundancy between objects and lockTableObject. The former contains all objects to be locked and the latter just the last one.
Please note that the lock table statement ends on mode keyword or on lockTableWaitOption which can end on wait keyword or on an integer value.
lockTableObject
The lockTableObject on line 49-55 defines the following fields:
schema, optional that refers to asqlNameidentifiertable, mandatory that refers to asqlNameidentifierdblink, optional that refers to aqualifiedNameidentifier
For the optional partitionExtensionClause no field is defined. I think this is wrong and should be fixed in a future version. Nonetheless it’s possible to find it in the generic children field.
partitionExtensionClause
The partitionExtensionClause on line 57-64 defines four partition variants. Each variant has a label – the token after the hash sign (#). Based on these labels ANTLR generates the following subclasses of the class PartitionExtensionClauseContext:
PartitionContextSubpartitionKeysContextSubpartitionContextSubpartitionKeysContext
It’s another good practice to define a label for an alternative. It simplifies finding classes in the parse tree using listeners or visitors and makes the parse tree more expressive. The next screenshots highlights the partition alternative in the ANTLR IntelliJ plugin. The ANTLR interpreter does not generate classes. Instead it shows the alternative after a colon. Either the ordinal number or the label, if available. However, it’s still a good representation of what you can expect at runtime of the parser generated by ANTLR.
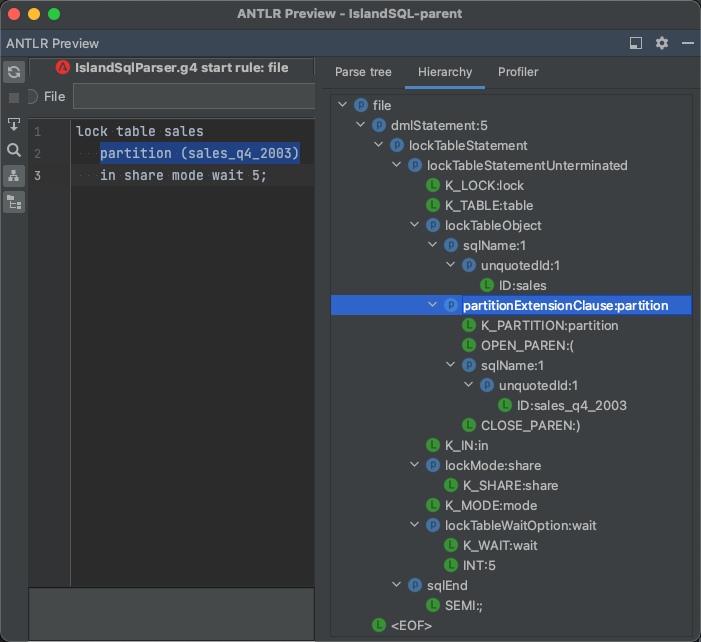
The alternatives for partitionKeys and subpartitionKeys define a field named keys with an array of expression.
expression
When working on a grammar you feel more than once like Hal fixing a light bulb. An expression is probably the most extensive part of the SQL grammar. It’s huge. It contains subqueries and a subquery is basically a select statement and a select statement uses conditions… Once we’ve done that, implementing the rest of the IslandSQL grammar is a piece of cake.
Therefore I decided to postpone the complete implementation and define just the bare minimum on line 66-71. Making the lock table statement work for partition keys based on integers, strings and variable names. – No datetime expressions yet.
lockMode
The Oracle Database allows 6 different lock modes. You find the valid allternatives on line 74-79.
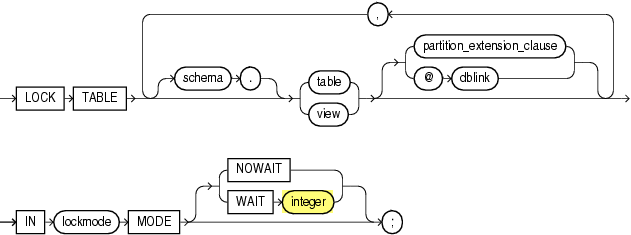
lockTableWaitOption
By default the Oracle Database waits indefinitely for the lock. You can override this behehaviour by one of the alternatives defined on line 83-84.
The grammar defines waitSeconds as an INT. That matches the definition in the SQL Language Reference of the Oracle Database 21c.
However, what is the meaning of integer in this case? Can we use an integer variable in PL/SQL? Can we use a decimal literal that can be converted to an integer such as 10.? Or can we use scientific notations such as 1e2 or even 1e2d? To know that, we have to try it out.
SQL> declare
2 co_wait_in_seconds constant integer := 10;
3 begin
4 lock table emp in exclusive mode wait co_wait_in_seconds;
5 end;
6 /
lock table emp in exclusive mode wait co_wait_in_seconds;
*
ERROR at line 4:
ORA-06550: line 4, column 42:
PL/SQL: ORA-30005: missing or invalid WAIT interval
ORA-06550: line 4, column 4:
PL/SQL: SQL Statement ignored
SQL> lock table emp in exclusive mode wait 10.;
Table(s) Locked.
SQL> lock table emp in exclusive mode wait 1e2;
Table(s) Locked.
SQL> lock table emp in exclusive mode wait 1e2d;
lock table emp in exclusive mode wait 1e2d
*
ERROR at line 1:
ORA-30005: missing or invalid WAIT intervalSo, we cannot use a variable/constant. But the scientific notation works and a decimal literal can be converted to an integer as long as we do not use the scientific notation.
I consider it a bug that we cannot use a variable/constant for the time to wait in PL/SQL. Especially since we can use static expressions in PL/SQL in various places, e.g. to define the size of varchar2 variable (since 12.2). It does not make sense to enforce the use of dynamic SQL to handle dynamic wait times in PL/SQL.
I can imagine that a future version of the Oracle Database will lift this restriction in the lock table statement. It would be a small change. Maybe not even documented. Therefore it might be a good idea to change this part of the grammar and support a bit more.
Identifiers
The Oracle Database allows the use of keywords as identifiers in a lot of places. Therefore we should allow the use of keywords such as lock in the lock table statement’s the identifiers schema, table and dblink. For that we created a rule named keywordAsId on line 91-105 that covers all keywords.
We defined ID in the lexer. It covers all identifiers. However, keywords have a higher priority in the lexer. Therefore we defined a new rule unquotedId that combines ID with keywordAsId.
The rule sqlName on line 112-115 combines unquotedId with the QUOTED_ID which we defined in the lexer.
And finally the rule qualifiedName on line 117-119 covers the unbounded concatenation of SqlName with a dot. The concatenation is optional. So a qualifiedName could look 100% the same as a sqlName. We could remove the schema in the rule lockTableObject and use qualifiedName for table like this:
lockTableObject:
table=qualifiedName
(
partitionExtensionClause
| (AT_SIGN dblink=qualifiedName)
)?
;This works and is a valid representation of the grammar. However, it’s less expressive. For dblink we must use qualifiedName. There is no predefined, binding naming scheme that covers the number of segments for a database link name.
SQL Statement End
The sqlEnd rule on the last line 125 defines the end of a SQL statement in SQL*Plus/SQLcl. We do not handle whitespace here as in the IslandSqlScopeLexer. As a result a lock table statement could be terminated with a slash on the same line. This might need some rework in a future version of the grammar.
Syntax Errors
Let’s look at a lock table statemant that uses an invalid lock mode.
SQL> lock table dept in access exclusive mode;
lock table dept in access exclusive mode
*
ERROR at line 1:
ORA-01737: valid modes: [ROW] SHARE, [[SHARE] ROW] EXCLUSIVE, SHARE UPDATEThis is a valid lock mode in PostgresSQL 15. Beside the lock mode the syntax of the lock table statement is different to the one in the Oracle Database 21c in various places. However, it should not be to complicated to define a grammar that can handle both syntaxes. We put this on the todo list and focus on supporting the Oracle Database grammar first.
However, how does our grammar deal with invalid SQL statements? – Here’s a screenshot of the extension for Visual Studio Code showing some lock table statements.
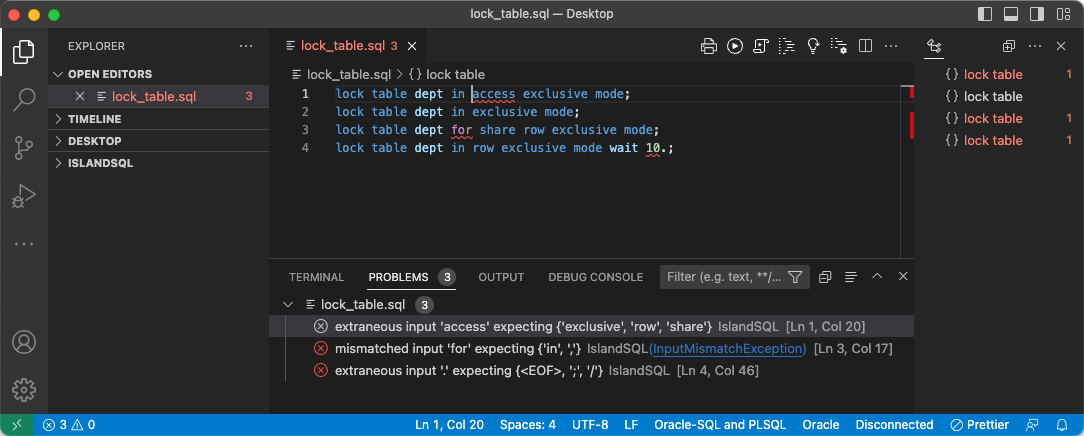
You see the word access wavy underlined in red. On mouse over you get the details displayed in the problems panel. Furthermore you see that lock_table.sql is displayed in red with a number 3 indicating that this file has three problems. And the outline view indicates problems by showing symbols in red.
That’s the cool thing when using an IDE supporting Micosoft’s Language Server Protocol. We just have to provide the syntax errors and the visualization happens automatically by the IDE in a standardized manner.
Right now the parser provides only syntax errors. However, it is relatively easy to implement an linter based on this grammar and provide the results as warnings. For example for lock table statements without a waitOption.
Outlook
We have not succeeded in fully supporting the lock table statement. There are cases that cannot yet be successfully parsed. I would like to address that. To do this, we need to look a bit more at literals and expressions before we deal with more DML statements.
Another topic is the support of more SQL dialects. I’d like to support PostgreSQL. Maybe it is a good time to start as soon as a DML statement is fully covered.
Stay tuned.
The post IslandSQL Episode 3: Lock Table appeared first on Philipp Salvisberg's Blog.