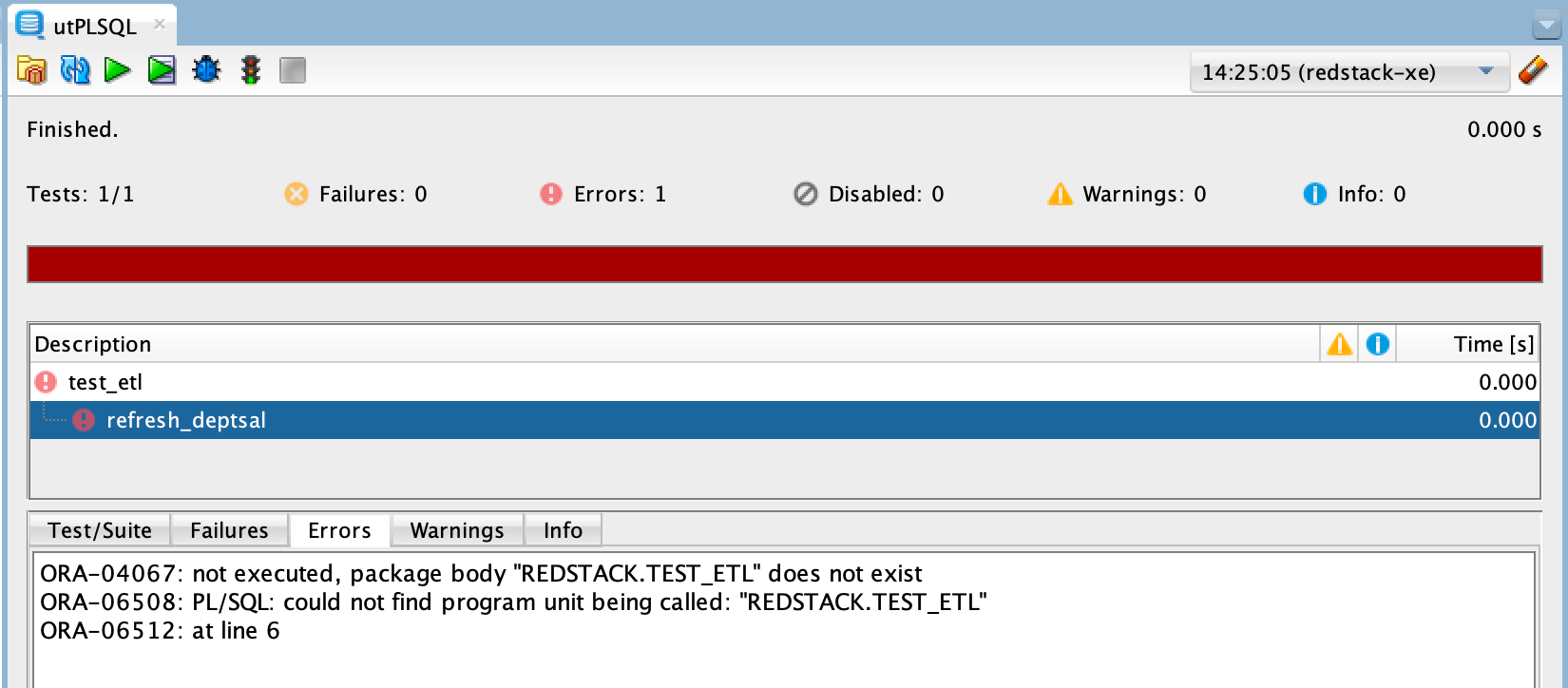
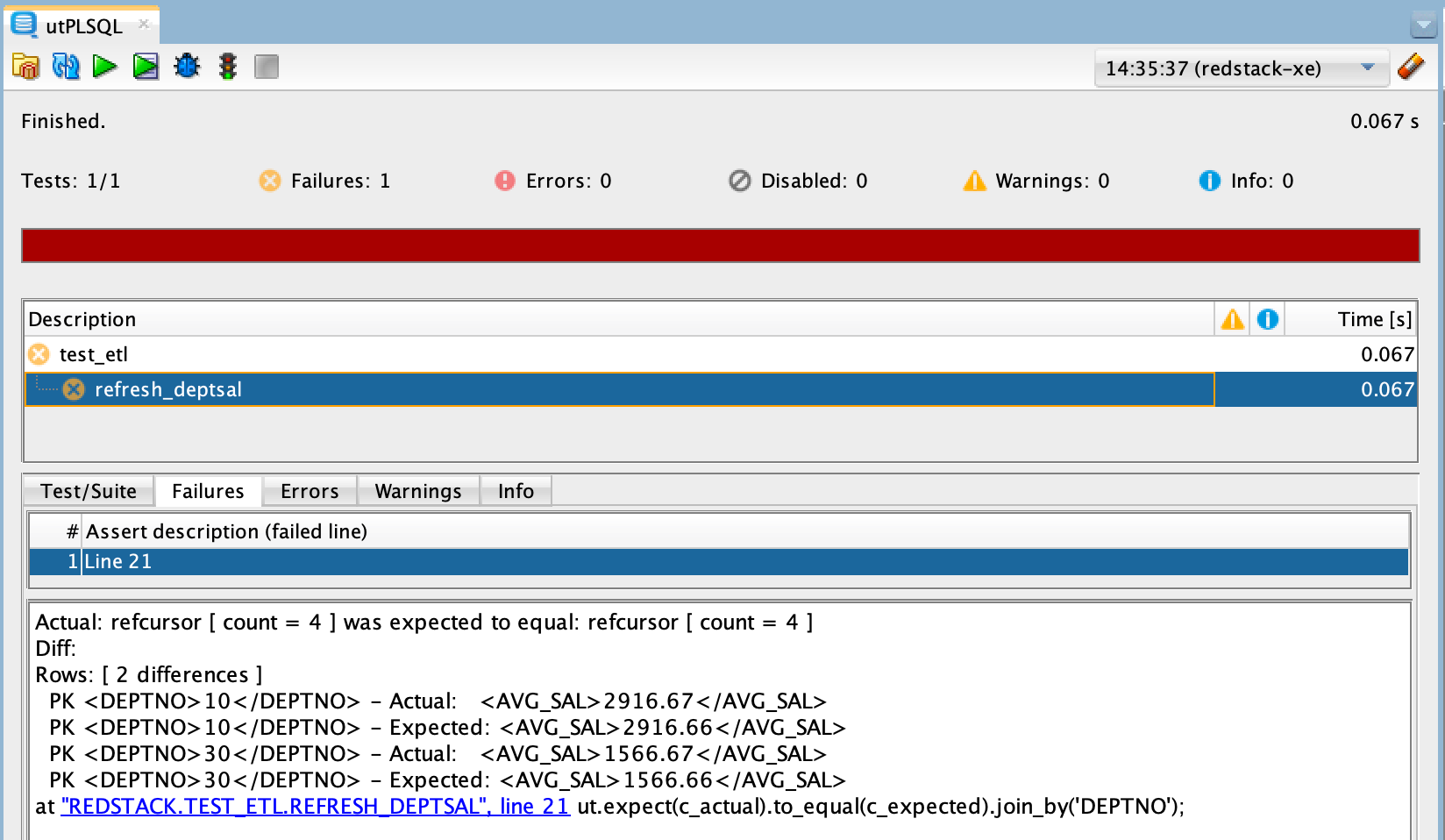
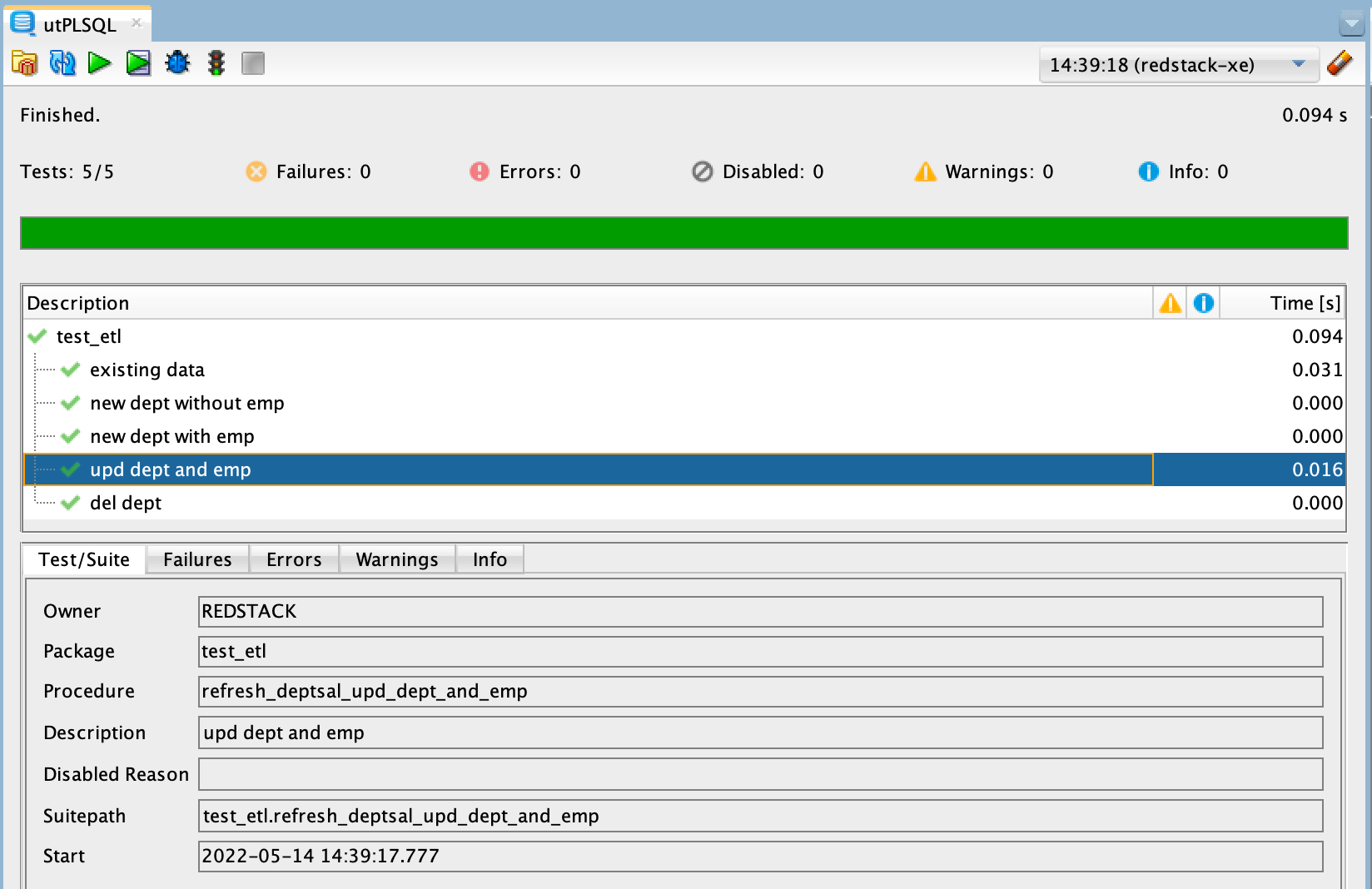
How Can We Work Around the Limitations?
We’ve seen the limitations of the current dbms_metadata API and the necessity to use string manipulation functions to fix invalid DDL.
There is no way to remove double quotes from quoted identifiers with dbms_metadata. However, as Connor McDonald demonstrated in his blog post we can remove them with some string acrobatics. Why not use a simple replace call? Because there are some rules to follow. A globally applied replace(..., '"', null) call would produce invalid code in many real life scenarios. We need a more robust solution.
Applying the rules in a code formatter can be such a robust solution.
Rules for Safely Removing Double Quotes from Quoted Identifiers
What are the rules to follow?
1. Is a SQL or PL/SQL Identifier
You have to make sure that the double quotes surround a SQL or PL/SQL identifier. Sounds logical. However, it is not that simple. Here are some examples:
create or replace procedure plsql_comment is
begin
-- "NOT_AN_IDENTIFIER"
/*
"NOT_AN_IDENTIFIER"
*/
null;
end;
/create or replace procedure plsql_string is
l_string1 varchar2(100 char);
l_string2 varchar2(100 char);
begin
l_string1 := '"NOT_AN_IDENTIFIER"';
l_string2 := q'[
"NOT_AN_IDENTIFIER"
]';
end;
/create or replace procedure plsql_conditional_compilation_text is
begin
$if false $then
Conditional compilation blocks can contain any text.
It does not need to be valid PL/SQL.
"NOT_AN_IDENTIFIER"
FTLDB and tePLSQL use this construct to store code templates in such blocks.
$end
null;
end;
/create or replace and resolve java source named "JavaString" as
public class JavaString {
public static String hello() {
return "NOT_AN_IDENTIFIER";
}
}
/You can solve the first three examples easily with a lexer. A lexer groups a stream of characters. Such a group of characters is called a lexer token. A lexer token knows the start and end position in a source text and has a type. The lexer in SQL Developer and SQLcl produces the following types of tokens:
- COMMENT (
/* ... */)
- LINE_COMMENT (
-- ...)
- QUOTED_STRING (
'string' or q'[string]')
- DQUOTED_STRING (
"string" )
- WS (space, tab, new line, carriage return)
- DIGITS (
0123456789 plus some special cases)
- OPERATION (e.g.
()[]^-|!*+.><=,;:%@?/~)
- IDENTIFIER (words)
- MACRO_SKIP (conditional compilation tokens such as
$if, $then, etc.)
We can simply focus on tokens of type DQUOTED_STRING and ignore tokens that are within conditional compilation tokens $if and $end.
To find out if a DQUOTED_STRING is part of a Java stored procedure is more difficult. Luckily SQL Developer’s parser cannot deal with Java stored procedures and produces a parse error. As a result, we just have to keep the code “as is” in such cases.
2. Consists of Valid Characters
According to the PL/SQL Language Reference an nonquoted identifier must comply with the following rules:
An ordinary user-defined identifier:
- Begins with a letter
- Can include letters, digits, and these symbols:
- Dollar sign ($)
- Number sign (#)
- Underscore (_)
What is a valid letter in this context? The SQL Language Reference defines a letter as an “alphabetic character from your database character set”. Here are some examples of valid letters and therefore valid PL/SQL variable names or SQL column names:
- Latin letters (
AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz)
- Umlauts (
ÄäËëÏïÖöÜüŸÿ)
- German Esszett (
ẞß), please note that the Oracle Database does not convert the case of an Esszett, because the uppercase Esszett exists offically only since 2017-03-29
- C cedilla (
Çç)
- Grave accented letters (
ÀàÈèÌìÒòÙù)
- Acute accented letters (
ÁáĆćÉéÍíÓóÚúÝý)
- Circumflex accented letters (
ÂâÊêÎîÔôÛû)
- Tilde accented letters (
ÃãÑñÕõ)
- Caron accented letters (
ǍǎB̌b̌ČčĚěF̌f̌ǦǧȞȟǏǐJ̌ǰǨǩM̌m̌ŇňǑǒP̌p̌Q̌q̌ŘřŠšǓǔV̌v̌W̌w̌X̌x̌Y̌y̌ŽžǮǯ)
- Ring accented letters (
ÅåŮů)
- Greek letters (
ΑαΒβΓγΔδΕεΖζΗηΘθΙιΚκΛλΜμΝνΞξΟοΠπΡρΣσΤτΥυΦφΧχΨψΩω)
- Common Cyrillic letters (
АаБбВвГгДдЕеЁёЖжЗзИиЙйКкЛлМмНнОоПпРрСсТтУуФфХхЦцЧчШшЩщЪъЫыЬьЭэЮюЯя)
- Hiragana letters (
ぁあぃいぅうぇえぉおかがきぎくぐけげこごさざしじすずせぜそぞただちぢっつづてでとどなにぬねのはばぱひびぴふぶぷへべぺほぼぽまみむめもゃやゅゆょよらりるれろゎわゐゑをんゔゕゖゝゞゟ)
The Oracle Database throws an ORA-00911: invalid character when this rule is violated.
Cause: The identifier name started with an ASCII character other than a letter or a number. After the first character of the identifier name, ASCII characters are allowed including “$”, “#” and “_”. Identifiers enclosed in double quotation marks may contain any character other than a double quotation. Alternate quotation marks (q’#…#’) cannot use spaces, tabs, or carriage returns as delimiters. For all other contexts, consult the SQL Language Reference Manual.
The cause for this error message seems to be outdated, inaccurate and wrong. Firstly, it limits letters to those contained in an ASCII character set. This limitation is not generally valid anymore. Secondly, it claims that an identifier can start with a number, which is simply wrong. Thirdly, ASCII characters and letters are used as synonyms, which is misleading.
However, there are still cases where an identifier is limited to ASCII characters or single byte characters. For example, a database name or a database link name. In the projects I know, the reduction of letters to A-Z for identifiers is not a problem. The use of accented letters in identifiers are typically oversights. Therefore, I recommend limiting the range of letters in identifiers to A-Z .
Checking this rule is quite simple. We just have to make sure that the quoted identifier matches this regular expression: ^"[A-Z][A-Z0-9_$#]*"$. This works with any regular expression engine, unlike ^"[[:alpha:]][[:alpha:]0-9_$#]*"$.
3. Is Not a Reserved Word
According to the PL/SQL Language Reference and the SQL Language Reference an nonquoted identifier must not be a reserved word.
If you are working with 3rd party parsers, the list of reserved words might not match the ones defined for the Oracle Database. In my case I also want to consider the reserved words defined by db* CODECOP. I’m using the following query to create a JSON array with currently 260 keywords:
select json_arrayagg(keyword order by keyword) as keywords
from (
-- reserved keywords in Oracle database 21.3.0.0.0 (ATP)
select keyword
from v$reserved_words
where (reserved = 'Y' or res_type = 'Y' or res_attr = 'Y' or res_semi = 'Y')
and keyword is not null
and regexp_like(keyword, '^[A-Z][A-Z0-9_$#]*$') -- valid nonquoted identifier
union
-- reserved keywords in db* CODECOP's PL/SQL parser 4.2.0
select keyword
from json_table(
'["AFTER","ALL","ALLOW","ALTER","ANALYTIC","AND","ANYSCHEMA","AS","ASC","ASSOCIATE","AUTHID","AUTOMATIC",
"AUTONOMOUS_TRANSACTION","BEFORE","BEGIN","BETWEEN","BULK","BY","BYTE","CANONICAL","CASE",
"CASE-SENSITIVE","CHECK","CLUSTER","COMPOUND","CONNECT","CONNECT_BY_ROOT","CONSTANT","CONSTRAINT",
"CONSTRUCTOR","CORRUPT_XID","CORRUPT_XID_ALL","CREATE","CROSSEDITION","CURRENT","CUSTOMDATUM",
"CYCLE","DB_ROLE_CHANGE","DECLARE","DECREMENT","DEFAULTS","DEFINE","DEFINER","DETERMINISTIC",
"DIMENSION","DISALLOW","DISASSOCIATE","DISTINCT","DROP","EACH","EDITIONING","ELSE","ELSIF",
"END","EVALNAME","EXCEPTION","EXCEPTION_INIT","EXCEPTIONS","EXCLUSIVE","EXTERNAL","FETCH",
"FOLLOWING","FOLLOWS","FOR","FORALL","FROM","GOTO","GRANT","GROUP","HAVING","HIDE","HIER_ANCESTOR",
"HIER_LAG","HIER_LEAD","HIER_PARENT","IF","IGNORE","IMMUTABLE","IN","INCREMENT","INDEX","INDICATOR",
"INDICES","INITIALLY","INLINE","INSERT","INSTEAD","INTERSECT","INTO","INVISIBLE","IS","ISOLATION",
"JAVA","JSON_EXISTS","JSON_TABLE","LATERAL","LIBRARY","LIKE","LIKE2","LIKE4","LIKEC","LOCK","LOGON",
"MAXVALUE","MEASURES","MERGE","MINUS","MINVALUE","MULTISET","MUTABLE","NAN","NAV","NCHAR_CS","NOCOPY",
"NOCYCLE","NONSCHEMA","NORELY","NOT","NOVALIDATE","NOWAIT","OF","ON","ONLY","OPTION","OR","ORADATA",
"ORDER","ORDINALITY","OVER","OVERRIDING","PARALLEL_ENABLE","PARTITION","PASSING","PAST","PIPELINED",
"PIVOT","PRAGMA","PRECEDES","PRECEDING","PRESENT","PRIOR","PROCEDURE","REFERENCES","REFERENCING",
"REJECT","RELY","REPEAT","RESPECT","RESTRICT_REFERENCES","RESULT_CACHE","RETURNING","REVOKE",
"SELECT","SEQUENTIAL","SERIALIZABLE","SERIALLY_REUSABLE","SERVERERROR","SETS","SHARE","SIBLINGS",
"SINGLE","SOME","SQL_MACRO","SQLDATA","STANDALONE","START","SUBMULTISET","SUBPARTITION",
"SUPPRESSES_WARNING_6009","THE","THEN","TO","TRIGGER","UDF","UNBOUNDED","UNDER","UNION",
"UNIQUE","UNLIMITED","UNPIVOT","UNTIL","UPDATE","UPSERT","USING","VALUES","VARRAY","VARYING",
"VIEW","WHEN","WHERE","WHILE","WINDOW","WITH","XMLATTRIBUTES","XMLEXISTS","XMLFOREST",
"XMLNAMESPACES","XMLQUERY","XMLROOT","XMLSCHEMA","XMLSERIALIZE","XMLTABLE"]',
'$[*]' columns (keyword path '$')
)
);The result can be used to populate a HashSet. This allows you to check very efficiently whether an identifier is a keyword.
Of course, such a global list of keywords is a simplification. In reality, the restrictions are context-specific. However, I consider the use of keywords for identifiers in any context a bad practice. Therefore, I can live with some unnecessarily quoted identifiers.
4. Is in Upper Case
This means that the following condition must be true: quoted_identifier = upper(quoted_identifier).
This does not necessarily mean that the identifier is case-insensitive as the following examples show:
set pagesize 100
column key format A3
column value format A5
set null "(-)"
-- OK, KEY/VALUE are clearly case-sensitive
select j.pair."KEY", j.pair."VALUE"
from json_table('[{KEY:1, VALUE:"One"},{KEY:2, VALUE:"Two"}]',
'$[*]' columns (pair varchar2(100) format json path '$')) j;
KEY VALUE
--- -----
1 One
2 Two
-- OK, KEY/VALUE are case-sensitive, but you have to "know" that
select j.pair.KEY, j.pair.VALUE
from json_table('[{KEY:1, VALUE:"One"},{KEY:2, VALUE:"Two"}]',
'$[*]' columns (pair varchar2(100) format json path '$')) j;
KEY VALUE
--- -----
1 One
2 Two
-- Oups, no error, but the result is wrong (all NULLs)
-- This is why you should not let the formatter change the case of your identifiers!
select j.pair.key, j.pair.value
from json_table('[{KEY:1, VALUE:"One"},{KEY:2, VALUE:"Two"}]',
'$[*]' columns (pair varchar2(100) format json path '$')) j;
KEY VALUE
--- -----
(-) (-)
(-) (-)You can check this rule in combination with the previous rule by using a case-insensitive regular expression, which is the default.
5. Is Not Part of a Code Section for Which the Formatter Is Disabled
When you use a formatter there are some code sections where you do not want the formatter to change it. Therefore we want to honor the marker comments that disable and enable the formatter.
Here is an example:
create or replace procedure disable_enable_formatter is
l_dummy sys.dual.dummy%type;
begin
-- @formatter:off
select decode(dummy, 'X', 1
, 'Y', 2
, 'Z', 3
, 0) "DECODE_RESULT" /* @formatter:on */
into "L_DUMMY"
from "SYS"."DUAL";
select "DUMMY" -- noformat start
into "L_DUMMY"
from "SYS"."DUAL" -- noformat end
where "DUMMY" is not null;
end;
/After calling the formatter we expect the following output (when changing identifier case to lower is enabled):
create or replace procedure disable_enable_formatter is
l_dummy sys.dual.dummy%type;
begin
-- @formatter:off
select decode(dummy, 'X', 1
, 'Y', 2
, 'Z', 3
, 0) "DECODE_RESULT" /* @formatter:on */
into l_dummy
from sys.dual;
select dummy -- noformat start
into "L_DUMMY"
from "SYS"."DUAL" -- noformat end
where dummy is not null;
end;
/To check this we can reuse the approach for quoted identifiers in conditional compilation text.
Removing Double Quotes from Quoted Identifiers with Arbori
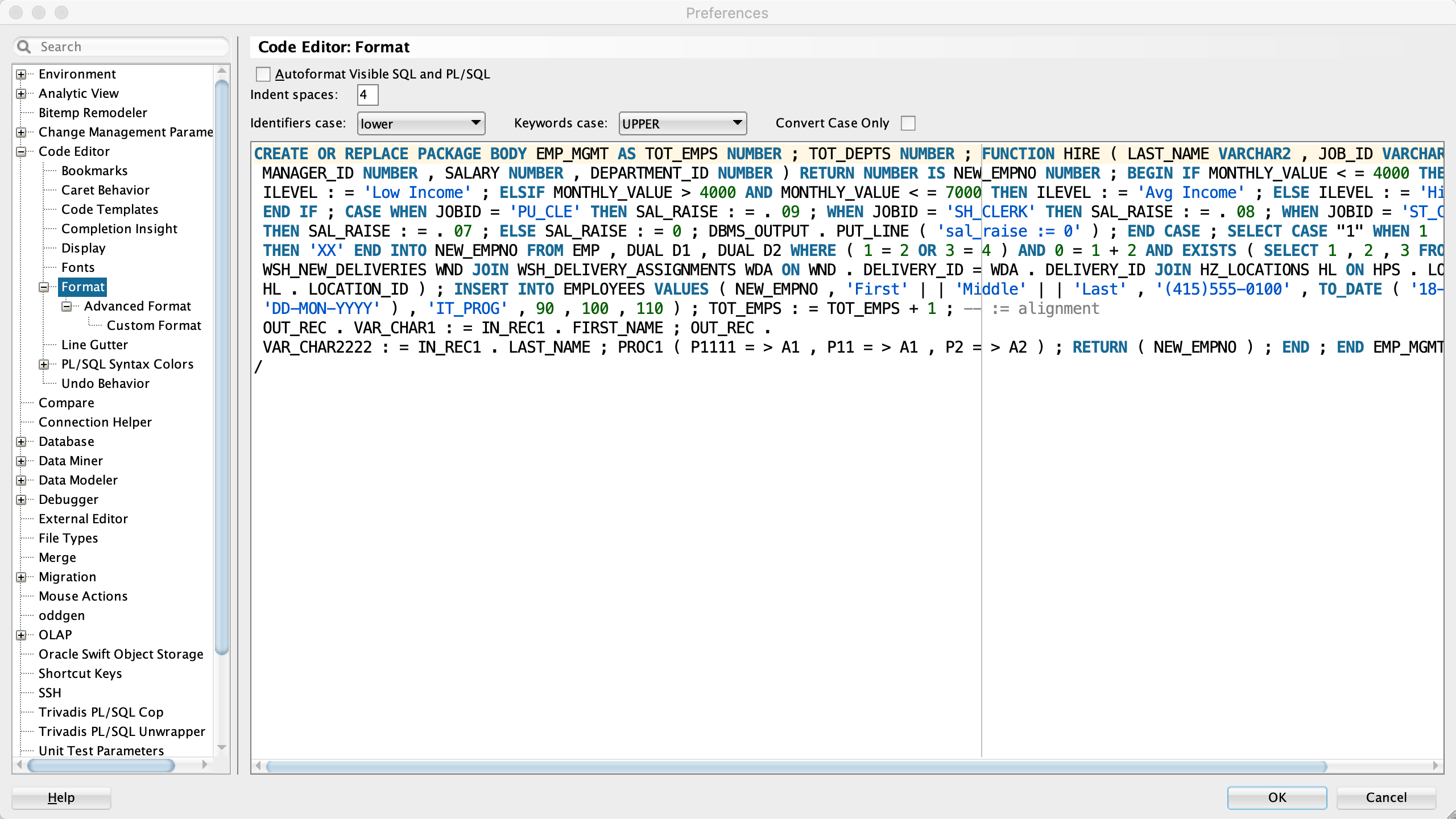
As mentioned at the beginning of the post, the current version of the PL/SQL & SQL Formatter Settings can safely remove double quotes from PL/SQL and SQL code.
Here are simplified formatter settings which can be imported into SQL Developer 22.2.1. The formatter with these settings only removes the double quotes from identifiers in a safe way and leaves your code “as is”. You can download these settings from this Gist.
<options>
<adjustCaseOnly>false</adjustCaseOnly>
<singleLineComments>oracle.dbtools.app.Format.InlineComments.CommentsUnchanged</singleLineComments>
<maxCharLineSize>120000</maxCharLineSize>
<idCase>oracle.dbtools.app.Format.Case.NoCaseChange</idCase>
<kwCase>oracle.dbtools.app.Format.Case.lower</kwCase>
<formatWhenSyntaxError>false</formatWhenSyntaxError>
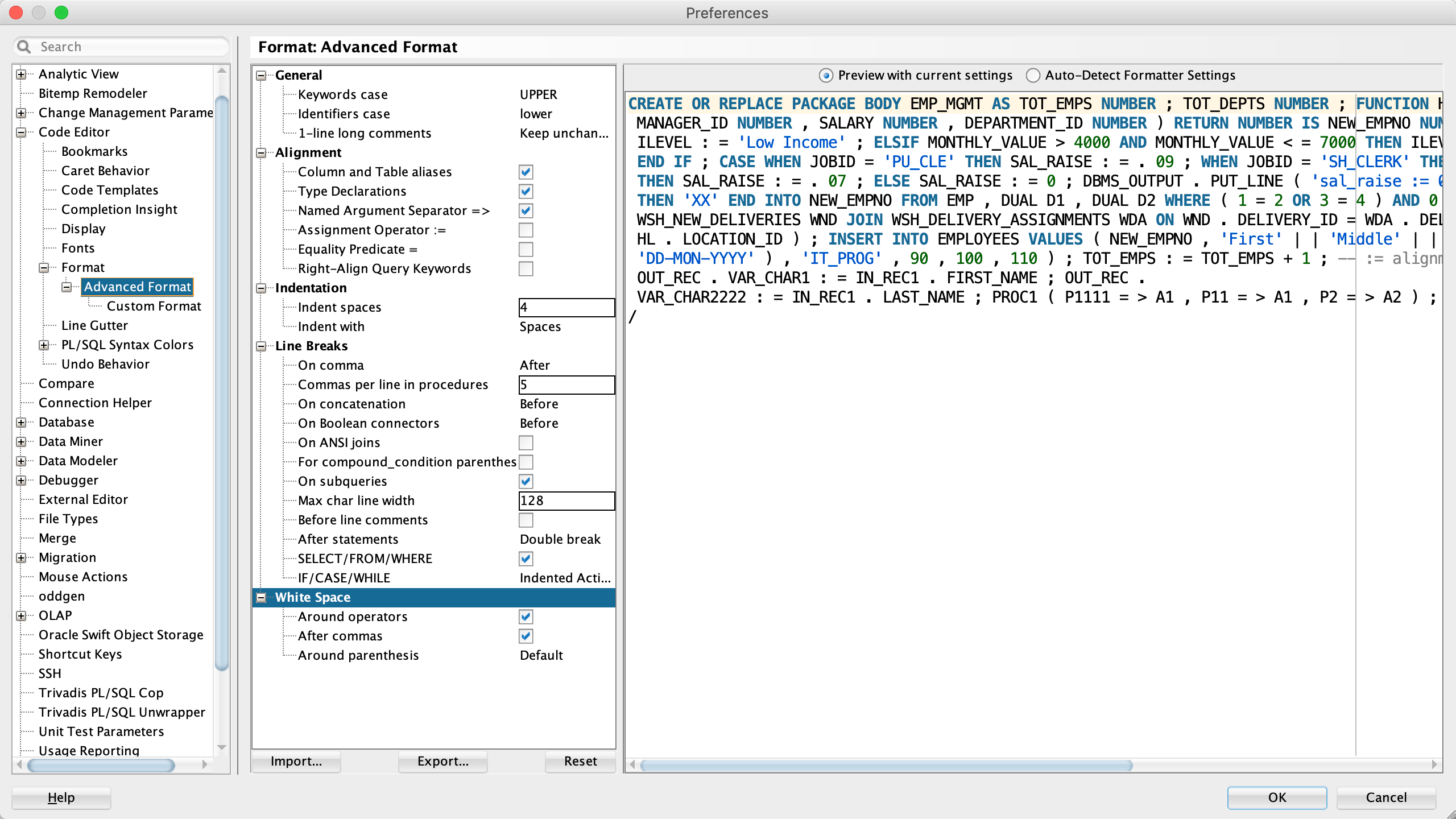
</options>Firstly, the option adjustCaseOnly ensures that the Arbori program is fully applied.
Secondly, the option singleLineComments ensures that the whitespace before single line comments are kept “as is”.
Thirdly, the maxCharLineSize ensures that no line breaks are added. The value of 120000 seems to be ridiculous high. However I’ve seen single lines of around hundred thousand characters in the wild.
Fourthly, the option idCase ensures that the case of nonquoted identifiers is not changed. This is important for JSON dot notation.
Fifthly, the option kwCase ensures that the case of keywords is also kept “as is”.
And Finally, the option formatWhenSyntaxError ensures that the formatter does not change code that the formatter does not understand. This is important to keep Java strings intact.
The value of all other options are irrelevant for the this Arbori program.
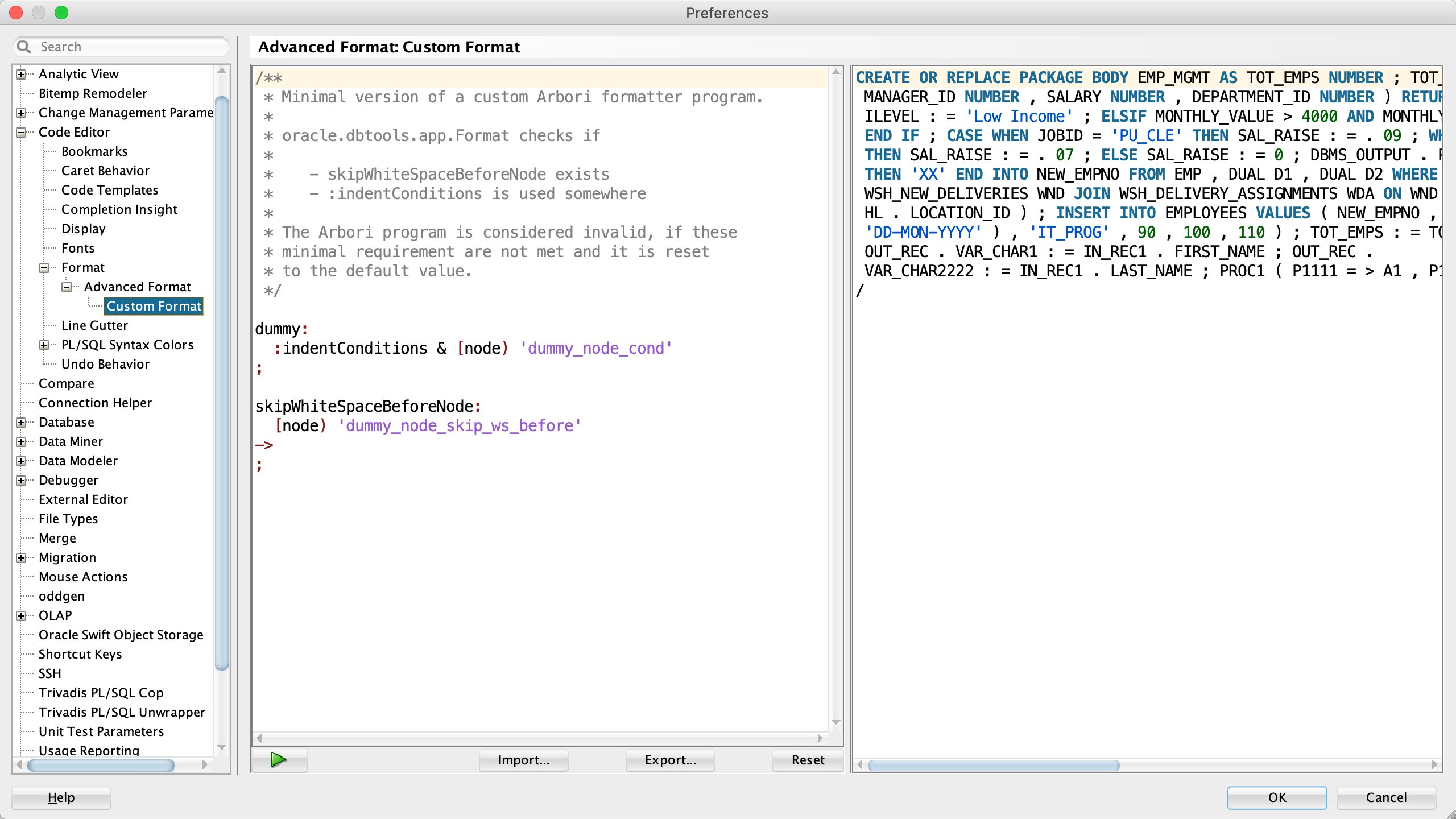
-- --------------------------------------------------------------------------------------------------------------------
-- Minimal Arbori program (expected by the formatter, also expected: "order_by_clause___0").
-- --------------------------------------------------------------------------------------------------------------------
include "std.arbori"
dummy: :indentConditions & [node) identifier;
skipWhiteSpaceBeforeNode: runOnce -> { var doNotCallCallbackFunction;}
dontFormatNode: [node) numeric_literal | [node) path ->;
-- --------------------------------------------------------------------------------------------------------------------
-- Keep existing whitespace.
-- --------------------------------------------------------------------------------------------------------------------
keep_significant_whitespace:
runOnce
-> {
var LexerToken = Java.type('oracle.dbtools.parser.LexerToken');
var tokens = LexerToken.parse(target.input, true); // include hidden tokens
var hiddenTokenCount = 0;
var wsBefore = "";
var Token = Java.type('oracle.dbtools.parser.Token');
for (var i in tokens) {
var type = tokens[i].type;
if (type == Token.LINE_COMMENT || type == Token.COMMENT || type == Token.WS ||
type == Token.MACRO_SKIP || type == Token.SQLPLUSLINECONTINUE_SKIP)
{
hiddenTokenCount++;
if (type == Token.WS) {
wsBefore += tokens[i].content;
} else {
wsBefore = "";
}
} else {
if (i-hiddenTokenCount == 0 && hiddenTokenCount == wsBefore.length) {
struct.putNewline(0, "");
} else if (wsBefore != " ") {
struct.putNewline(i-hiddenTokenCount, wsBefore);
}
wsBefore = "";
}
}
}
-- --------------------------------------------------------------------------------------------------------------------
-- Enforce nonquoted identifiers.
-- --------------------------------------------------------------------------------------------------------------------
enforce_nonquoted_identifiers:
runOnce
-> {
var offOnRanges = [];
var populateOffOnRanges = function(tokens) {
var off = -1;
for (var i in tokens) {
var type = tokens[i].type;
if (type == Token.LINE_COMMENT || type == Token.COMMENT) {
if (tokens[i].content.toLowerCase().indexOf("@formatter:off") != -1
|| tokens[i].content.toLowerCase().indexOf("noformat start") != -1)
{
off = tokens[i].begin;
}
if (off != -1) {
if (tokens[i].content.toLowerCase().indexOf("@formatter:on") != -1
|| tokens[i].content.toLowerCase().indexOf("noformat end") != -1)
{
offOnRanges.push([off, tokens[i].end]);
off = -1;
}
}
}
}
}
var inOffOnRange = function(pos) {
for (var x in offOnRanges) {
if (pos >= offOnRanges[x][0] && pos < offOnRanges[x][1]) {
return true;
}
}
return false;
}
var HashSet = Java.type('java.util.HashSet');
var Arrays = Java.type('java.util.Arrays');
var reservedKeywords = new HashSet(Arrays.asList("ACCESS","ADD","AFTER","ALL","ALLOW","ALTER","ANALYTIC","AND",
"ANY","ANYSCHEMA","AS","ASC","ASSOCIATE","AUDIT","AUTHID","AUTOMATIC","AUTONOMOUS_TRANSACTION","BEFORE",
"BEGIN","BETWEEN","BULK","BY","BYTE","CANONICAL","CASE","CASE-SENSITIVE","CHAR","CHECK","CLUSTER","COLUMN",
"COLUMN_VALUE","COMMENT","COMPOUND","COMPRESS","CONNECT","CONNECT_BY_ROOT","CONSTANT","CONSTRAINT",
"CONSTRUCTOR","CORRUPT_XID","CORRUPT_XID_ALL","CREATE","CROSSEDITION","CURRENT","CUSTOMDATUM","CYCLE",
"DATE","DB_ROLE_CHANGE","DECIMAL","DECLARE","DECREMENT","DEFAULT","DEFAULTS","DEFINE","DEFINER","DELETE",
"DESC","DETERMINISTIC","DIMENSION","DISALLOW","DISASSOCIATE","DISTINCT","DROP","EACH","EDITIONING","ELSE",
"ELSIF","END","EVALNAME","EXCEPT","EXCEPTION","EXCEPTIONS","EXCEPTION_INIT","EXCLUSIVE","EXISTS","EXTERNAL",
"FETCH","FILE","FLOAT","FOLLOWING","FOLLOWS","FOR","FORALL","FROM","GOTO","GRANT","GROUP","HAVING","HIDE",
"HIER_ANCESTOR","HIER_LAG","HIER_LEAD","HIER_PARENT","IDENTIFIED","IF","IGNORE","IMMEDIATE","IMMUTABLE",
"IN","INCREMENT","INDEX","INDICATOR","INDICES","INITIAL","INITIALLY","INLINE","INSERT","INSTEAD","INTEGER",
"INTERSECT","INTO","INVISIBLE","IS","ISOLATION","JAVA","JSON_EXISTS","JSON_TABLE","LATERAL","LEVEL","LIBRARY",
"LIKE","LIKE2","LIKE4","LIKEC","LOCK","LOGON","LONG","MAXEXTENTS","MAXVALUE","MEASURES","MERGE","MINUS",
"MINVALUE","MLSLABEL","MODE","MODIFY","MULTISET","MUTABLE","NAN","NAV","NCHAR_CS","NESTED_TABLE_ID","NOAUDIT",
"NOCOMPRESS","NOCOPY","NOCYCLE","NONSCHEMA","NORELY","NOT","NOVALIDATE","NOWAIT","NULL","NUMBER","OF",
"OFFLINE","ON","ONLINE","ONLY","OPTION","OR","ORADATA","ORDER","ORDINALITY","OVER","OVERRIDING",
"PARALLEL_ENABLE","PARTITION","PASSING","PAST","PCTFREE","PIPELINED","PIVOT","PRAGMA","PRECEDES",
"PRECEDING","PRESENT","PRIOR","PROCEDURE","PUBLIC","RAW","REFERENCES","REFERENCING","REJECT","RELY",
"RENAME","REPEAT","RESOURCE","RESPECT","RESTRICT_REFERENCES","RESULT_CACHE","RETURNING","REVOKE","ROW",
"ROWID","ROWNUM","ROWS","SELECT","SEQUENTIAL","SERIALIZABLE","SERIALLY_REUSABLE","SERVERERROR","SESSION",
"SET","SETS","SHARE","SIBLINGS","SINGLE","SIZE","SMALLINT","SOME","SQLDATA","SQL_MACRO","STANDALONE",
"START","SUBMULTISET","SUBPARTITION","SUCCESSFUL","SUPPRESSES_WARNING_6009","SYNONYM","SYSDATE","TABLE",
"THE","THEN","TO","TRIGGER","UDF","UID","UNBOUNDED","UNDER","UNION","UNIQUE","UNLIMITED","UNPIVOT","UNTIL",
"UPDATE","UPSERT","USER","USING","VALIDATE","VALUES","VARCHAR","VARCHAR2","VARRAY","VARYING","VIEW",
"WHEN","WHENEVER","WHERE","WHILE","WINDOW","WITH","XMLATTRIBUTES","XMLEXISTS","XMLFOREST","XMLNAMESPACES",
"XMLQUERY","XMLROOT","XMLSCHEMA","XMLSERIALIZE","XMLTABLE"));
var isKeyword = function(token) {
return reservedKeywords.contains(token.content.replace('"', ""));
}
var isUnquotingAllowed = function(token) {
var Pattern = Java.type("java.util.regex.Pattern");
if (!Pattern.matches('^"[A-Z][A-Z0-9_$#]*"$', token.content)) {
return false;
}
if (isKeyword(token)) {
return false;
}
return true;
}
var findAndConvertQuotedIdentifiers = function() {
var tokens = LexerToken.parse(target.input,true); // include hidden tokens
populateOffOnRanges(tokens);
var StringBuilder = Java.type('java.lang.StringBuilder');
var newInput = new StringBuilder(target.input);
var delpos = [];
var conditionalBlock = false;
for (var i in tokens) {
var type = tokens[i].type;
if (type == Token.MACRO_SKIP) {
var content = tokens[i].content.toLowerCase();
if (content.indexOf("$if ") == 0) {
conditionalBlock = true;
} else if (content.indexOf("$end") == 0) {
conditionalBlock = false;
}
}
if (type == Token.DQUOTED_STRING && isUnquotingAllowed(tokens[i])
&& !inOffOnRange(tokens[i].begin) && !conditionalBlock)
{
delpos.push(tokens[i].begin);
delpos.push(tokens[i].end-1);
}
}
var i = delpos.length - 1;
while (i >= 0) {
newInput.deleteCharAt(delpos[i]);
i--;
}
target.input = newInput.toString();
}
var updateParseTreeAndTokenList = function() {
var Parsed = Java.type('oracle.dbtools.parser.Parsed');
var SqlEarley = Java.type('oracle.dbtools.parser.plsql.SqlEarley')
var defaultTokens = LexerToken.parse(target.input);
var newTarget = new Parsed(target.input, defaultTokens, SqlEarley.getInstance(),
Java.to(["sql_statements"], "java.lang.String[]"));
target.src.clear();
target.src.addAll(newTarget.src);
}
// main
findAndConvertQuotedIdentifiers();
updateParseTreeAndTokenList();
}
-- --------------------------------------------------------------------------------------------------------------------
-- Define identifiers (relevant for keyword case and identifier case)
-- --------------------------------------------------------------------------------------------------------------------
analytics: [identifier) identifier & [call) analytic_function & [call = [identifier;
ids: [identifier) identifier;
identifiers: ids - analytics ->;Firstly, the lines 1 to 8 are required by the formatter. They are not interesting in this context.
Secondly, the lines 9 to 42 are the heart of a lightweight formatter. This code ensures that all whitespace between all tokens are kept. Therefore, the existing format of the code remains untouched. Read this blog post to learn how SQL Developer’s formatter works.
Thirdly, the lines 43 to 173 remove unnecessary double quotes from identifiers. We store the position of double quotes to be removed on line 147 and 148 in an array named delpos while processing all tokens from start to end. The removal of the double quotes happens on line 153 while processing delpos entries from end to start.
And finally, the lines 174-180 define an Arbori query named identifier. The formatter uses this query to divide lexer tokens of type IDENTIFIER into keywords and identifiers. This is important to ensure that the case of identifiers is left “as is” regardless of the configuration of kwCase.
Doesn’t Connor’s PL/SQL Function Do the Same?
No, when you look closely at the ddl_cleanup.sql script as of 2022-03-02, you will find out that the ddl function has the following limitations:
- Quoted identifiers are not ignored in
- Single and multi-line comments
- Conditional compilation text
- Code sections for which the formatter is disabled
- Java Strings are treated as quoted identifiers
- Reserved keywords are not considered
- Nonquoted identifiers are changed to lower case, which might break code using JSON dot notation
It just shows that things become complicated when you don’t solve them in the right place. In this case dbms_metadata‘s XSLT scripts. dbms_metadata knows what’s an identifier. It can safely skip the enquoting process if the identifier is in upper case, matches the regular expression ^[A-Z][A-Z0-9_$#]*$ and the identifier is not a reserved keyword. That’s all. The logic can be implemented in a single XSL template. We API users on the other side must parse the code to somehow identify quoted identifiers and its context before we can decide how to proceed.
Formatting DDL Automatically
You can configure SQL Developer to automatically format DDL with your current formatter settings. For that you have to enable the option Autoformat Dictionary Objects SQL as in the screenshot below:
![Autoformat DDL]()
Here’s the result for the deptsal view using the PL/SQL & SQL Formatter Settings:
![Autoformat in Action]()
The identifiers in upper case were originally quoted identifiers. By default, we configure the formatter to keep the case of identifiers. This ensures that code using JSON dot notation is not affected by a formatting operation.
Processing Many Files
SQL Developer is not suited to format many files. However, you can use the SQLcl script or the standalone formatter to format files in a directory tree. The formatter settings (path to the .xml and .arbori file) can be passed as parameters. I recommend using the standalone formatter. It uses the up-to-date and much faster JavaScript engine from GraalVM. Furthermore, the standalone formatter also works with JDK 17, which no longer contains a JavaScript engine.
You can download the latest tvdformat.jar from here. Run java -jar tvdformat.jar to show all command line options.
Summary
If your code base contains generated code, then it probably also contains unnecessarily quoted identifiers. Especially if dbms_metadata was used to extract DDL statements. Removing these double quotes without breaking some code is not that easy. However, SQL Developer’s highly configurable formatter can do the job, even without actually formatting the code.
I hope that some of the shortcomings of dbms_metadata will be addressed in an upcoming release of the Oracle Database. Supporting nonquoted identifiers as an additional non-default option should be easy and not so risky to implement.
Anyway, instead of just detecting violations of G-2180: Never use quoted identifiers, it is a good idea to be able to correct them automatically.
Please open a GitHub issue if you encounter a bug in the formatter settings. Thank you.